Today we’re going to look at how to create a Machine Learning model. Not with Python or Tensorflow or Spark, but we’re going to create a Machine Learning model using SQL.
What is Machine Learning?
Machine Learning (ML), a subset of Artificial Intelligence (AI), is the study of computer algorithms that solve a problem by learning from underlying patterns in data, as opposed to statistical heuristics or rule based programming
To get an answer to a question, a traditional approach has been to define rules (if… then… else…) either based on intuition or based on our inference of the historical data. But the rules can quickly get complicated and it may not be practical to implement all the rules required to get to the answer.
For example, if you’re trying to predict the fare of an Uber cab when going from point A to point B, there might be too many rules for that algorithm.
- If the pickup location is X…
- If the drop-off location is X…
- If the trip start time is X….
- If it is a weekday, then…. If it is a weekend then….
- If the distance to be travelled is X…
- If the time required to cover that distance is X….
- what about traffic? If the traffic is low, medium, high?…
These rules might get complicated and there might be many more that impact the cab fare.

Machine Learning takes a different approach to provide an intelligent answer to this problem. Using ML, you can create an algorithm that learns from historical data of such trips. The model will be able to develop intelligence about this topic and will be able to predict the fare for a trip in the future. The algorithm will learn all the rules from the data, without being explicitly explaining what those rules are.
Mathematically, a Machine Learning algorithm, produces a mathematical equation between various features of the trip (the inputs) and the fare (the output).
f(distance, traffic, pickup location, drop-off location.... ) = fare
This equation is called the Machine Learning model. The model can then be used to make prediction for a new trip if we know all the inputs parameters (features of the trip).
Let us implement a simple fare prediction model today. Generally data scientists use Python and various ML libraries to implement an ML model, we will use SQL (Structured Query Language).
The Data
We will be using the data from Chicago Taxi Trips. This data is available in BigQuery as a part of the Public Datasets.
BigQuery is a Global Data Warehouse available on the Google Cloud Platform.
We’ll use data from the entire year of 2020 and for the purpose of this demo. We’ll only look at 1 feature, i.e. the distance for a trip to predict the fare for that trip. Also, for simplicity, we are going to trim the edges, we are only going to look at trips that were between $3 to $100 USD in fare and between 2.5 miles to 50 miles in trip distance. This is what data looks like.
select
fare,
trip_miles
FROM
`bigquery-public-data.chicago_taxi_trips.taxi_trips`
where
fare between 3 and 100 and
trip_miles between 2.5 and 50 and
trip_start_timestamp between "2020-01-01" and "2021-01-01"There are 1,274,704 rows of data available to learn from.
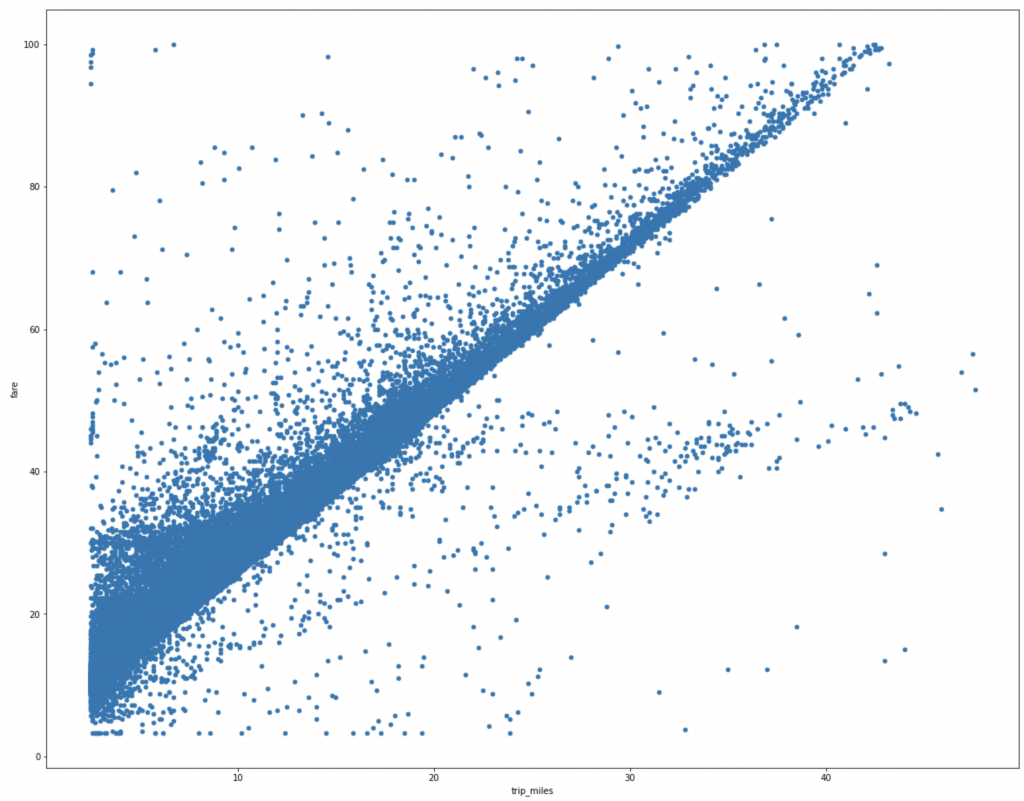
Now obviously in the real world, the fare of a taxi trip depends on a lot of other features like the time of the day, the day of the week, the traffic, the pickup and drop-off location and so on. It is clear from the graph above that although the distance appears to be strongly correlated to the fare, there’s quite a bit of noise and that probably corresponds to contribution from other features. But for the purpose of this demo, let’s stick to only one feature “trip_miles”.
Training
BigQuery ML makes it extremely simple to train a Machine Learning model. You just need to add a couple of lines on top of your select statement that is mentioned above.
CREATE OR REPLACE MODEL `bqml.taxi_fare_prediction`
OPTIONS(
model_type='linear_reg'
, input_label_cols=['fare']
, L1_REG = 1
) AS
select
fare,
trip_miles
FROM
`bigquery-public-data.chicago_taxi_trips.taxi_trips`
where
fare between 3 and 100 and
trip_miles between 2.5 and 50 and
trip_start_timestamp between "2020-01-01" and "2021-01-01"
Here you can see that we did only add 2 lines.
CREATE OR REPLACE MODEL `bqml.taxi_fare_prediction`The create model (add ‘or replace’ if you’re retraining the model) statement tells BigQuery that you’re triyng to train the model. The model name is provided in this statement.
OPTIONS(
model_type='linear_reg'
, input_label_cols=['fare']
, L1_REG = 1
) ASBigQuery ML provides a bunch of options. We’ll be using 3 of these options in our code today.
- model_type: We will be training a linear regression model. This model establishes a linear relationship between the inputs and the outputs.
- input_label_cols: We have to tell BigQuery ML which column from the dataset is our “label”. This is the column that the model will predict once it has learnt from the data.
- L1_REG: This parameter provides The amount of L1 regularization applied. This is required so that the model does not overfit to the training data.
When I clicked “Run”, the query took 1 min 23 sec to execute. In other words, it took 1 min 23 sec to train the model.
The loss curve for the model is made available on the BigQuery console.

BigQuery provides the evaluation metrics for the model.
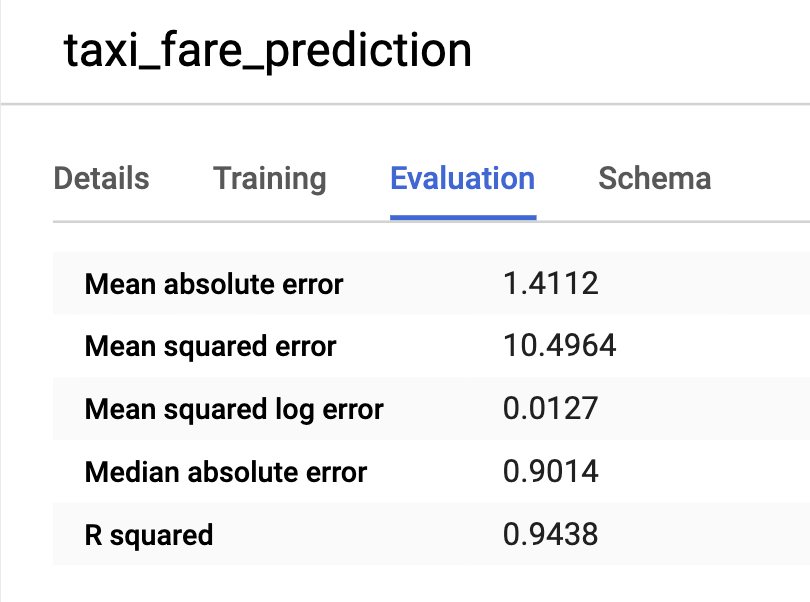
You can see that the R squared is 0.9438, which is pretty good. In lay man terms, R squared measures how close does your model predict to the actual values. An R squared of 1 means the model predicts perfectly each time.
Batch Prediction
Now that we have a model trained, let’s run some predictions and see how well it works out.
Let’s predict for all the trips from 2021. We’ll make a prediction for various trip_miles values and compare the prediction to the average fare that the cabbies charged in 2021 for that distance.
select
trip_miles,
avg(fare) as fare
FROM
`bigquery-public-data.chicago_taxi_trips.taxi_trips`
where
fare between 3 and 100 and
trip_miles between 2.5 and 50 and
trip_start_timestamp > "2021-01-01"
group by trip_milesThis gives us our test data. Now pass this data to ML.PREDICT function.
SELECT
*
FROM
ML.PREDICT(MODEL `bqml.taxi_fare_prediction`,
(
select
trip_miles,
avg(fare) as fare
FROM
`bigquery-public-data.chicago_taxi_trips.taxi_trips`
where
fare between 3 and 100 and
trip_miles between 2.5 and 50 and
trip_start_timestamp > "2021-01-01"
group by trip_miles
))
order by trip_miles
You can see that our prediction aligns very well with the test data.
Streaming Prediction
This is great, but what about real-time prediction? Can we create an API that allows us to predict on-demand? This will allow us to integrate this model with an app, similar to how Uber works.
Let’s start with “exporting” the model. Go to the model in the BigQuery console and click on “Export Model”.

BQ will ask you for a GCS location. Just provide a folder path.

Now go to Vertex AI > Models.
On the models page, click to import a model.
Import your model using the GCS path where you had saved the model.

This will import the model into Vertex AI Models tab.

Next, let’s go to the Vertex AI > Endpoints tab and click on “Create Endpoints”
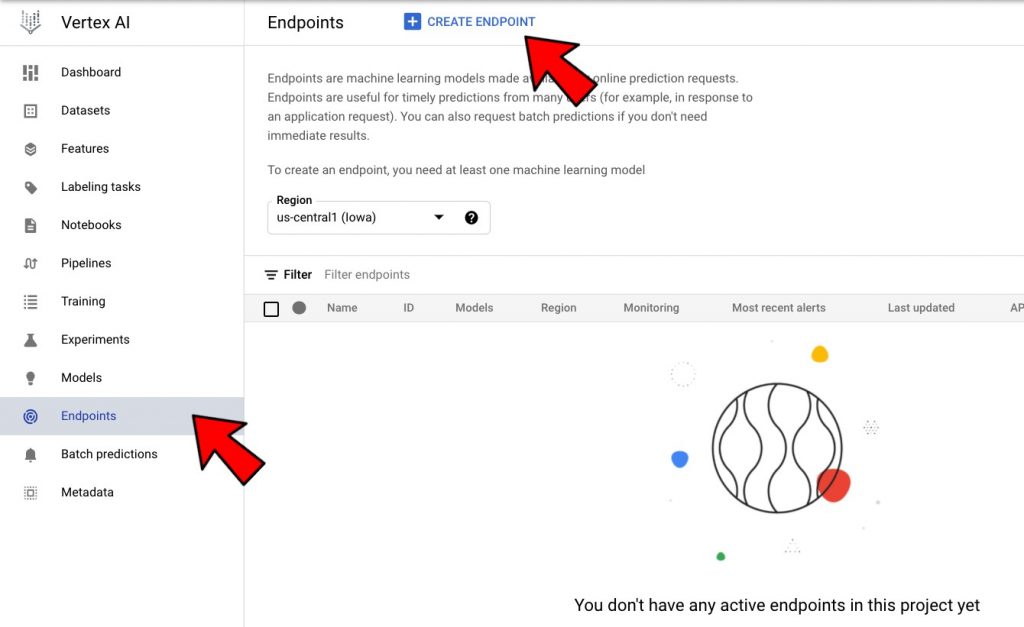
Follow the wizard to create an endpoint. see below.
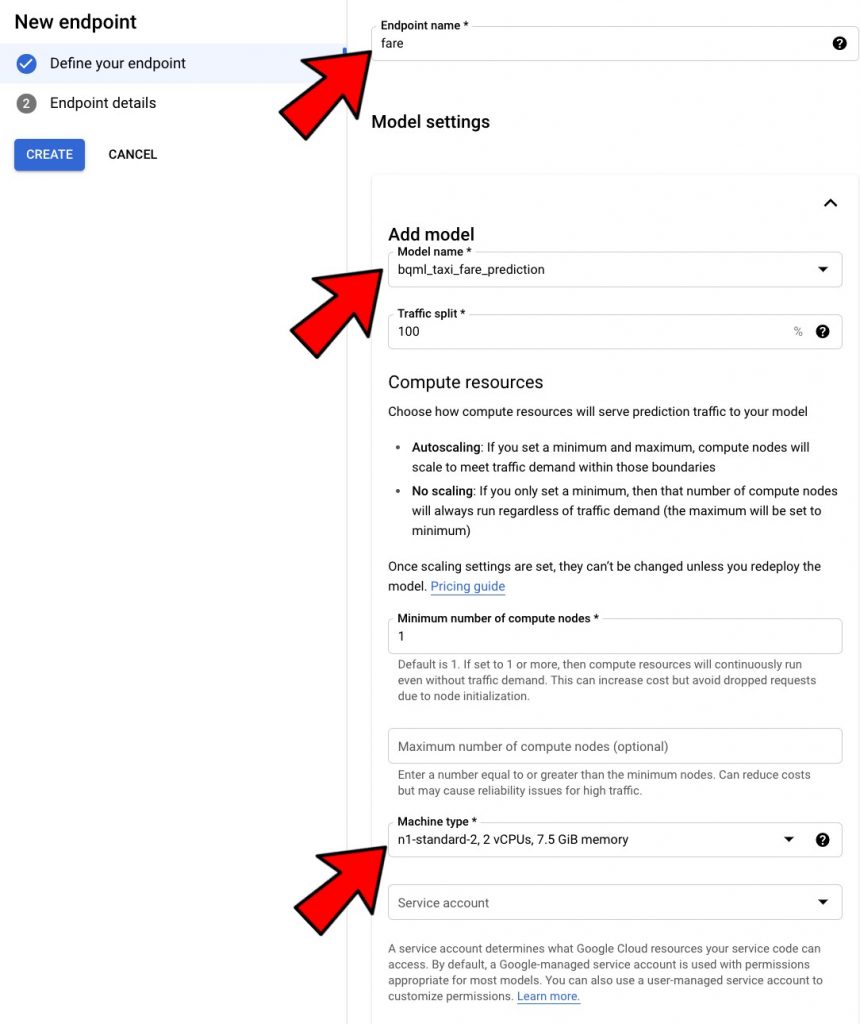
This should give you an endpoint that can be used for real-time prediction.

Now test this out with Postman
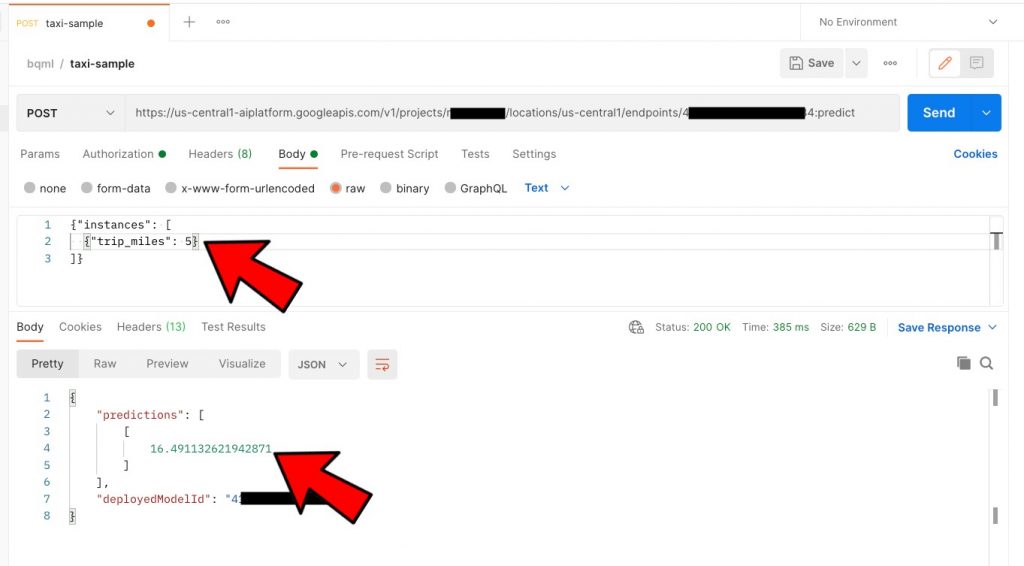
Now that you have a REST API, you can go ahead and integrate this within any app…. 😎
Conclusion
Hope this was useful and helps you get started with Machine Learning with just SQL. You don’t need to know Python, Tensorflow, Spark or anything else; if you know SQL, you can ML!
Not only can you ML, you can do with with using Managed Services on Google Cloud, so now you don’t have to worry about infrastructure management for Machine Learning either.
Let’s create some models!